在外匯交易中的過度最佳化是什麼?詳細介紹對策以及回測時的注意事項
過度最佳化是在程式交易中真正獲取盈利的主要障礙之一。
找到有優勢的策略非常重要,如果不能判斷所使用的程式是否有優勢,就不能獲取盈利。
本篇文章將介紹如何避免過度最佳化,如果透過回測看出程式的真實情況。
表面上的優勢
一個可以檢測出價格波動非隨機性的週期和條件,並能在正確時間採取正確方向部位的程式,在實盤操作中也可以獲取盈利。如果在持倉期間,價格走勢是隨機或是找不到建倉的方向的話,那麼任何邏輯都不會帶來優勢。
在開發程式中,為了最佳化參數、修改邏輯、增加過濾器等目的,有可能會多次來回查看相同歷史數據。
在來回修改的過程中,程式設置就會最佳化為不能預測隨機的價格波動,因此就會出現不能複製的表面優勢。
因為時不能複製的優勢,所以在實盤中會起不到任何作用。
樣本外測試(Out-of-sample test)
在過度最佳化對策中,廣泛使用的有效措施就是樣本外測試。如果過度最佳化是由於在同一歷史數據上來回往返所造成的話,在來回往返的程式調整期間之外,需要留出只能一次通過的程式測試期間,這將成為收集現實驗證數據的有效方法。
回測的目的時驗證而不是調整程式。
回測是為了淘汰沒有優勢的程式,而不是為了改善程式進行回測。
從調整程式的數據中挑選出令人滿意的數據,並把它當做歷史表現,這將是一個非常嚴重的問題。
在樣本外測試中最具有代表性的方法就是先行走勢法
下圖是使用2013年初至2022年末為止的歷史數據進行的先行走勢測試。
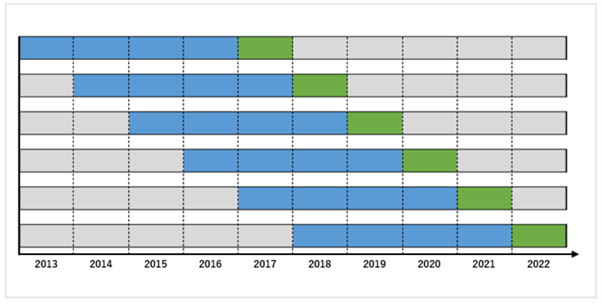
藍色是程式的最佳化訓練期間(樣本內),綠色是測試期間(樣本外)。
-
1.在2013~2016年進行最佳化,在2017年進行測試
2.在2014~2017年進行最佳化,在2018年進行測試
3.在2015~2018年進行最佳化,在2019年進行測試
4.在2016~2019年進行最佳化,在2020年進行測試
5.在2017~2020年進行最佳化,在2021年進行測試
6.在2018~2021年進行最佳化,在2022年進行測試
訓練數據(樣本內)由於是在歷史數據來回往返的非現實數據,所以,這個數據在評價程式時不能使用。在評價程式時使用測試數據(樣本外)非常重要。
如果在先行走勢法中收集的樣本外數據(綠色)具有優勢的話,那麼在今後的實盤操作期間(紅色箭頭)中獲利的可能性也將提高。
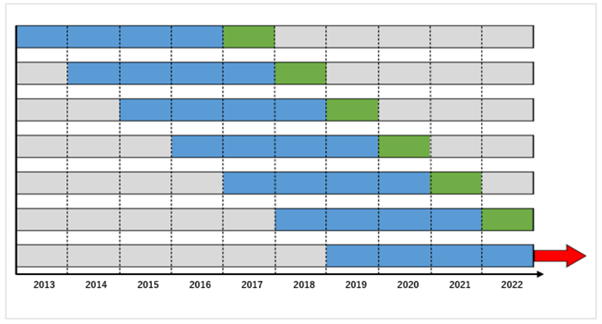
2種過度最佳化
最佳化不應用於提高樣本內的表現,而是應該為了找到在樣本外中起到作用的參數。如果在樣本內最佳化後而發現的參數在樣本外不能發揮作用的話,就沒有任何意義。
對樣本內和樣本外都進行最佳化。
如果對樣本內過度最佳化的話,樣本內的系統將會預測與邏輯毫無相關的價格波動和噪音。
預測不出的價格波動在樣本外當然也不能預測,所以,在樣本內中發現的參數和最適合樣本外的參數之間就會出現較大的差異。
樣本外過度最佳化的原因是什麼。
例如,在做完先行走勢測試後有想到新的策略,然後修改邏輯再一次進行先行走勢測試。
上面有介紹過度最佳化會在歷史數據中多次往返,但是,像這次只是做了2次先行走勢測試,也就是在修改邏輯之前只做了2次測試,然後就根據結果選擇了邏輯。
參數最佳化只是被邏輯最佳化所取代,所以在開發者還沒有意識到的情況下測試數據變為訓練數據。
再舉一個例子。
例如,在開發程式中進行了100次回測。但是,其大部分結果對於開發者來說都不滿意,只有少數結果達到開發者的標準。
這裡假設有1%的概率,一個本來沒有優勢的程式偶然因為歷史數據中的噪音等原因,導致達到了標準。
也就是說,在100次的回測中,大概有1次把沒有優勢的程式誤判斷為有優勢。
就像過度最佳化一樣,因為偶然預測到了不能預測的東西,所以,在實盤中的成績也會出現偏離。
樣本內的過度最佳化對策
樣本內的過度最佳化的難易程度會受到樣本規模大小和程式的複雜性影響。考察樣本內的過度最佳化對策。
對策1:增大樣本規模
樣本規模(最佳化期間的交易次數)如果太小的話受到噪音的影響就會變大,最佳化的結果就會極端的上下跳動。噪音的影響會隨著樣本的規模而變小。
樣本規模大的時候沒有什麼問題,樣本規模小的時候需要估計在偶然的情況下也許會出現大幅跳動。
以下的曲線圖中對推定的母體變異數進行反算,可以看出樣本規模越大分散越小,精確度也會隨之上升。
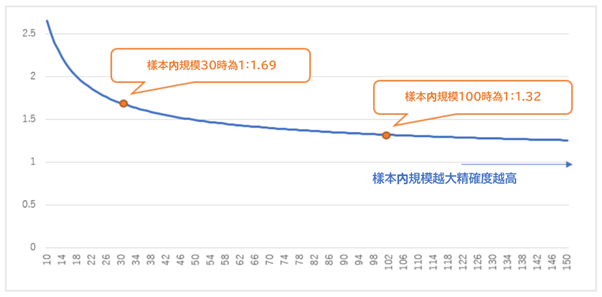
樣本規模越小為什麼評價指標就會變得越嚴格。
以下計算公式顯示了隨機交易n次的盈利係數(PF)會在95%以內的概率。
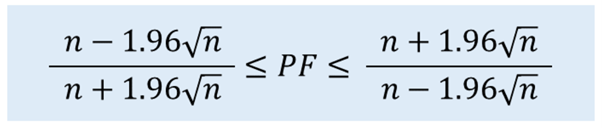
隨機交易的PF上限是交易次數越多約會小於1.0,而交易次數越少數值將會越大。
以下是關於最佳化後的PF除以隨機交易的PF上限公式的說明。
- 交易次數越多,數值越傾向於最佳化後的PF
- 交易次數越少數值越小
- 隨機交易的PF超過最佳化後的PF時,數值將達到1.0以上

也就是,把PF/PFr作為最佳化的目標函數將會成為一個對策。
對策2:程式不要太複雜
邏輯越複雜,就越有可能對價格波動做出反應,拾取歷史數據中的噪音。理想的邏輯是對「可以預測的行情」做出反應,對噪音等其他價格波動不作任何反應。
如果程式簡單到連可預測的行情都不能說明的話也不會產生優勢,而過於複雜的話回測也會變得更難。
- 根據想要做的行情持倉
- 不要亂加下單過濾
- 盡量減少需要最佳化的參數
過於複雜的程式雖然容易過度最佳化,但是,也並不是說越簡單越好。
一般來說,可預測的行情都是用最小的設置可以解釋,而「為了防止過度最佳化不做最佳化」的選擇卻大部分都是錯誤。
在Art Colins的著作《Market Beaters》中也寫到,有的參數需要透過最佳化才能判斷是否堅固。。
接下來舉例介紹需要最佳化的參數。
有一個簡單的程式就是在「5的倍數日期的8:30買入美元/日元,在8:55(電匯中間價)平倉」。
這是因為日本企業習慣在5的倍數日期支付所產生的現象,這個策略就是針對在於中間價之前容易上漲的反常現象。
重要的是在中間價平掉多頭部位,而下單的8:30這個時間反而不太重要。
如果不把這個程式最佳化的話會怎麼樣。
從過去的價格波動來看,實際上在8:30之前更早的時間就容易上漲,如果不最佳化的話,就會容易錯過這段時間。
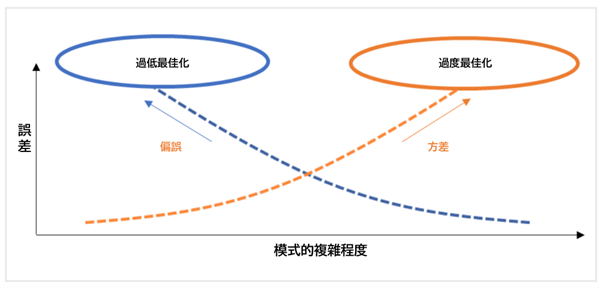
在機器學習領域有一個廣為人知的現象,即一個模型過於簡單或訓練不足,導致較大的誤差,稱之為偏誤,相反,一個模式過於複雜或訓練過度,導致較大的誤差,稱之為方差。
偏誤和方差是不能同時存在的關係。
所以,不要過度簡單或複雜,重要的是找到平衡。
對策3:根據最佳化結果確認堅固性
在最佳化時也需要關注最好結果以外的數值。對於只要稍微修改成為最好結果的參數就會導致結果有很大變動的程式,可以稱之為非常脆弱的程式。
相反,對於即便修改一些參數也不會影響結果,怎麼選擇參數都會有良好結果程式,可能會更加堅固。
對於修改一些參數也有穩定結果的程式,即便在實盤中出現變化,也有可能長期穩定盈利。
脆弱的程式因為會拾取一些偶然的噪音,所以結果也會變得非常片面,也就是說有極大可能時過度最佳化。
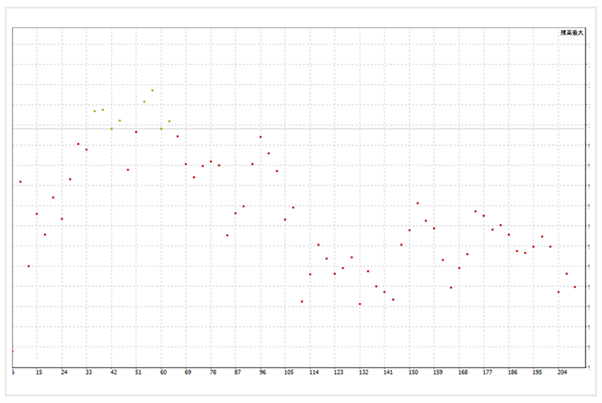
下圖是脆弱程式的最佳化結果。
良好結果只佔整體的幾個部分。
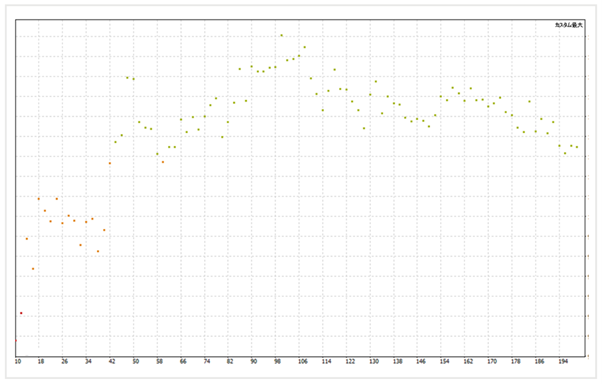
下面時堅固程式的最佳化結果。
可以看出,整體上都處於良好結果。
對策4:不選擇最好結果
默默地觀察整個最佳化結果,可以看出是一個山形。最好結果並不意味著時最優的參數,在山的頂峰附近才是最優的參數。
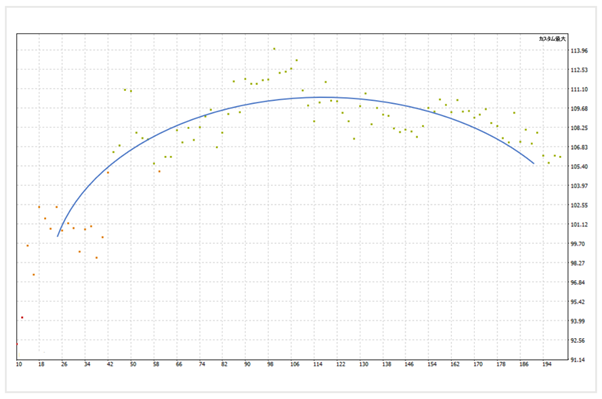
當參數連續變化時,山形趨勢逐漸顯示出適合於「可預測的交易機會」。
這裡的微小變化是因為拾取了噪音的影響,所以,明顯突出於頂部的地方有可能是過度最佳化。
重要的是選擇山頂附近的參數,忽略微小的變化。
樣本內的評價
如果可以在樣本內防止過度最佳化的話,樣本內的最優參數和樣本外的最優參數大概是一致的。樣本外的驗證數據收集完後,可以對樣本外的週期參數進行隨機變化。
透過確認樣本內的最優參數在隨機結果優秀成績的百分比,可以評價最佳化是否成功。
在隨機結果優秀成績的百分比越高,過度最佳化的可能性越低。
樣本外的過度最佳化對策
樣本外的過度最佳化原因在上面已有講過。樣本外決不允許在歷史數據之間來回往來。
應該注意在歷史數據之間往來的行為除了最佳化以外,還包含對邏輯和交易品種等的改變。
即使是用於實盤的一次性樣本外數據,也有可能意外融入樣本外週期的噪音,表現出超出其真正的潛力。
如果做了100個沒有優勢的程式,也許會有一個偶然超常發揮,但是,這個是不可複製的。
關於樣本噪音
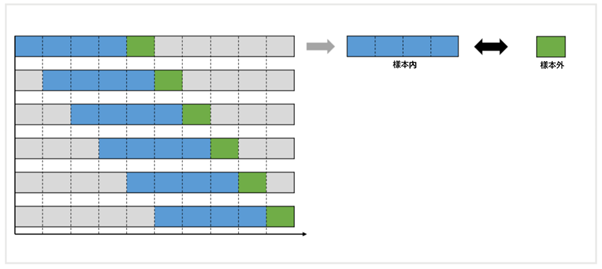
下圖是先行走勢法和沒有進行任何最佳化的單一回測相比較。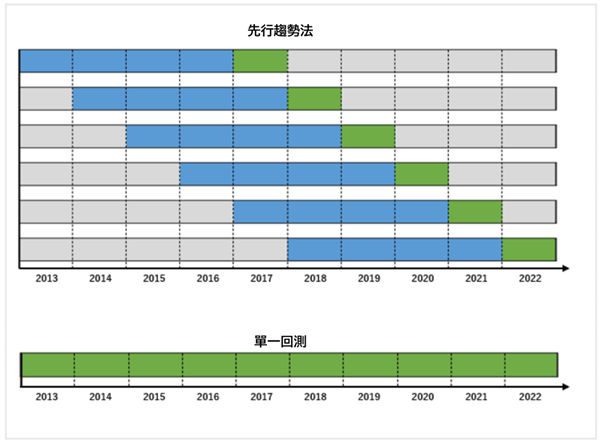
先行走勢法和單一回測相比較,先行走勢的樣本外週期會更短一些。
在樣本內的說明中有介紹到樣本規模越大越不容易出現過度最佳化,對於樣本外也是如此。
正如說明的那樣,因為有一些參數需要最佳化來調查特徵,而且還有測試程式穩健性的目的,所以完全沒有最佳化的單一測試並不是一個好主意。
在最佳化的同時增加樣本外週期的一種方法就是K拆交叉驗證。
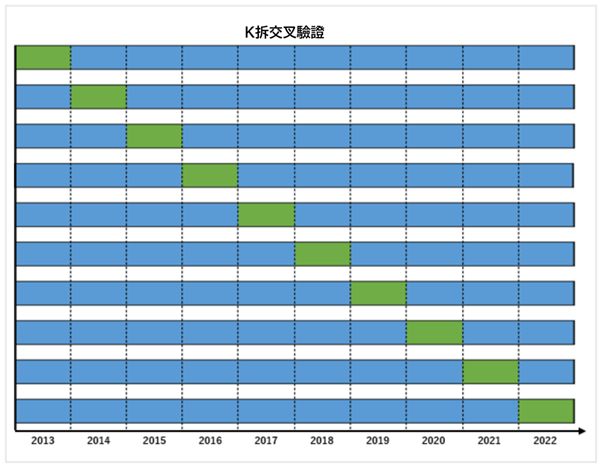
這個方法與先行趨勢法相比,可以增大樣本內和樣本外的樣本規模。
不過,這個方法也有缺點。
先行趨勢法中的樣本外週期和樣本內週期的時間序列都很真實,而K拆交叉驗證是用比樣本外週期更接近當前幾年的數據進行最佳化。
因為使用未來的數據,所以需要注意不要把不知道的信息洩露到樣本外週期。
關於回測途徑
以上所述的先行趨勢法和K拆交叉驗證都有一個相同的缺點,就是只能驗證一條回測途徑。下面介紹關於這個問題的解決方法,組合分割交叉驗證(CPCV)。
下圖顯示CPCV可以生成多條回測途徑。
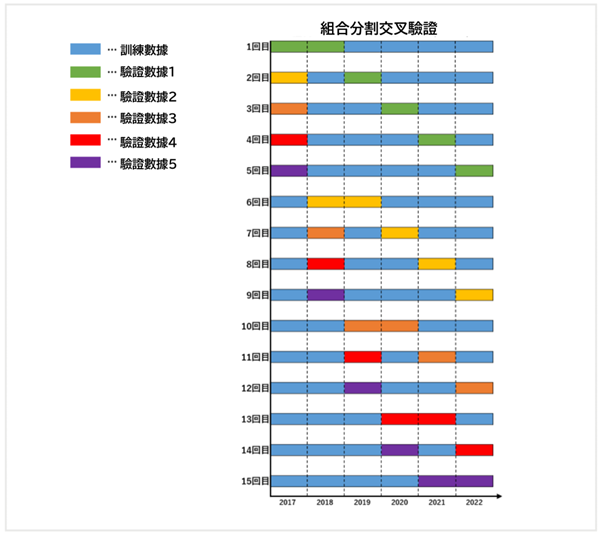
這個圖雖然只生成了5個回測途徑,如果交易頻度足夠高的話,可以生成幾百幾千個回測途徑。
多次驗證數據的不同之處在於其訓練的的時期,其中也有一些觸及上限和下限的結果混合在一起。
先行趨勢法和K拆交叉驗證的驗證數據只有一個,所以,觸及上限和下限也注意不到。
下面舉例介紹。
使用先行趨勢法進行的一組4年最佳化和1年測試的結果被認為有優勢。
用相同程式再次進行一組5年最佳化和1年測試的回測結果卻沒有優勢。
在第1次和第2次的回測中只是稍微修改了先行趨勢法的設置,但是,結果卻大有不同,就會擔心程式是否穩健。
由於先行趨勢法和K拆交叉驗證的缺點就是只能生成1個回測途徑,所以,即便出現這種問題也注意不到。
如果要用夏普比率來評價的話,先行趨勢法是基於單一的夏普比率,而CPCV卻可以得到多個夏普比率的分佈。
關於洩露
在回測的測試期間中,不應該給程式提供當時還不知道的信息。2022年美元/日元的匯率大幅上漲。
如果開發者已經知道這個信息,設定為「在2022年積極買入美元/日元」的話,回測結果雖然很好,但是,對於在2022年做測試的程式來說是還不知道的信息。
把獲取還不知道的信息稱之為洩露。
樣本外測試分為訓練數據和測試數據,在進行回測時,如果在訓練數據和測試數據之間沒有空隙的話,就有可能出現洩露。
這是因為如果是預測一週之後的程式的話,最多會有一週的數據有可能會與測試數據重疊。
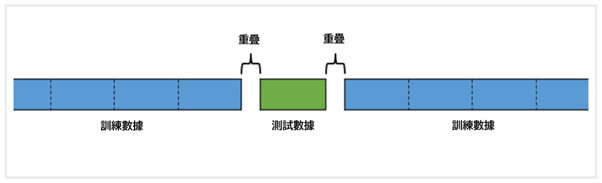
這種空出重疊期的措施被稱為淨化,這也是CPCV(組合分割交叉驗證)的重要技術。
除了淨化以外,對歷史數據追溯計算的技術指標等也會成為洩露的原因。
例如,使用1個月的移動平均線的話,需要空出1個月的時間。
這個被稱為禁令。
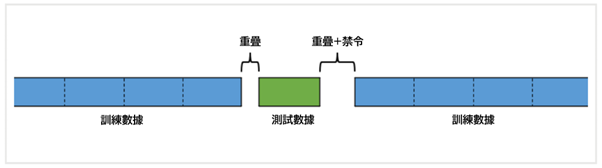
如果在先行趨勢法或CPCV中進行的樣本外測試的次數,也就是訓練數據和測試數據的接觸越多成績越好的話,有可能出現了洩露。
將EA自動程式交易應用於外匯與差價合約交易中

我們以圖文形式詳細介紹有關EA自動程式交易的基本知識,以及在MT4/MT5平台上的安裝、參數設定方法、編碼等等內容。另外,對持有OANDA帳戶的客戶,還可以免費使用我們的獨有EA與指標工具。




