什麼是均值回歸策略?介紹使用共整合ADF檢定的交易策略
均值回歸策略是在量化交易中常用的一種交易策略。
如果在價格變動中可以發現不隨機的均值回歸慣性的話,就可以在超買時賣出、超賣時買入,從而在交易中獲得優勢。
本篇文章將介紹作為均值回歸策略的統計套利(Statistical Arbitrage:StatArb)以及從數學上產生均值回歸慣性的共整合法。
統計套利
統計套利是均值回歸策略中的一種。一般常見的統計套利就是根據2種交易品種的相對價格進行交易判斷。
也就是說,並不是直接判斷超買超賣,而是相對與其他品種,該品種是超買還是超賣。
雖然是套利交易,但是與無風險且有利可圖的套利不同,這是一種在短期內並不知道是否會出現盈虧,是需要多次測試,從長期來看可以盈利的交易策略之一。
下面介紹一個統計套利的一個實例。
2個交易品種的組合最好具有很高的相關性。
當2個具有相關性的品種的價格差(點差)出現均值回歸時,就會產生統計套利的機會。
在價格差出現均值回歸慣性時,在點差暫時擴大後回歸到均值時可以做多或做空。
在判斷與其他品種相比是否超買或超賣時,如果可以從經濟學觀點上解釋其中一個品種與另外一個品種的相關性是高估還是低估時,可以提高判斷的準確度。
什麼是均值回歸
透過隨機與均值回歸相比較,確認在時間序列數據中均值回歸是什麼樣的狀態。隨機的示例
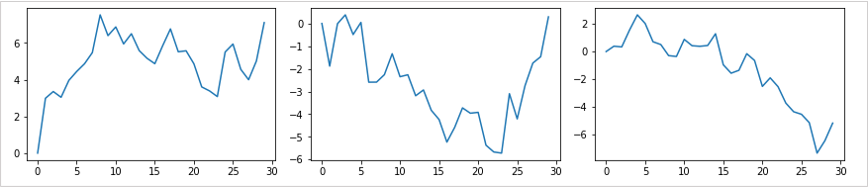
均值回歸的示例
隨機走勢是指在前一個數據中加入隨機數據的時間序列數據,均值回歸是在時間序列的中心有一個軸心,隨機就像是在其附近不均衡的變化數據。
隨機走勢就是一種價格決定與過去數據無關的狀態。
一個時間序列的均值和方差保持不變的特性被稱為靜止性。
這種靜止性或者靜止性所擁有的可以顯示靜止過程,是分析時間序列時非常重要的概念。
為了了解什麼是靜止過程,需要確認滯後1的自回歸過程(AR(1)過程)是否處於靜止狀態。
AR(1)過程是指「依賴前一個數據的時間序列的靜止過程」,代表現在的行情與前一個行情具有一定相關性的時間序列數據。

AR(1)過程可以用以上公式表示。
白噪音是時間序列數據的隨機成分。
為了可以更加容易理解,這裡將常數項一直視為0。

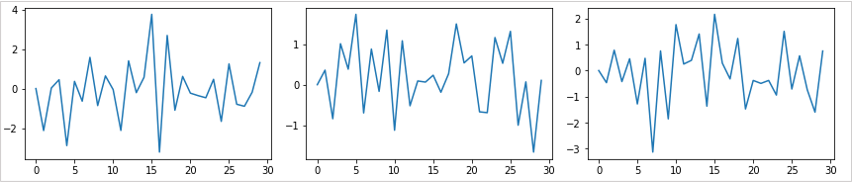
從左至右是顯示φ = -0.5、φ = 0.0、φ = 0.5、φ=1.0變化的曲線圖。
當φ = -0.5時,上下震盪最為劇烈,越往右邊來,曲線圖的震盪就越加平穩。
當φ = 1.0是,時間序列數據是在前一個數據中加入了隨機數據,這個條件與隨機走勢一樣,不會回歸到均值。
這種 φ的絕對值小於 1.0 的時間序列數據被稱為靜止過程,而 φ = 1.0 的時間序列數據被稱為單位根過程。
成為靜止過程,代表擁有回歸均值的特性。
在判斷均值回歸策略是否成立時,確認時間序列是否有靜止過程也是一種方法。
確認時間序列數據是否有靜止的方法之一就是ADF檢定。
ADF檢定是一種假設「時間序列有單位根」的檢定。
如果不具有這一假設的話,也就代表這個時間序列很有可能不是隨機走勢。
下面介紹一個使用Python的statsmodels庫進行ADF檢定的示例。
```
import yfinance as yf
from statsmodels.tsa.stattools import adfuller
# 獲取USD/JPY的數據
pair = 'JPY=X'
data = yf.download(pair, start='2022-04-01', end='2022-09-01')
usd_jpy_data = data['Close']
# ADF檢定
adf_test_result = adfuller(usd_jpy_data)
# 顯示結果
print('ADF Statistic:', adf_test_result[0])
print('p-value:', adf_test_result[1])
print('Critical Values:')
for key, value in adf_test_result[4].items():
print('\t%s: %.3f' % (key, value))
```
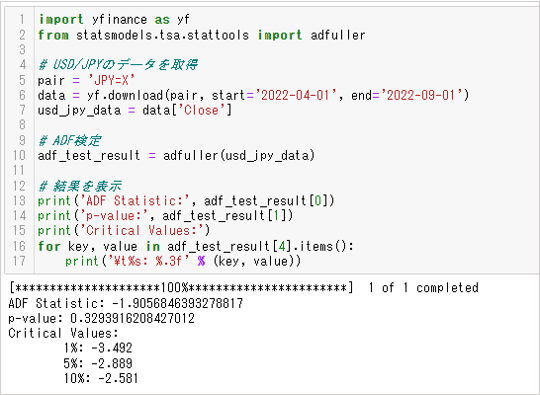 輸出數據如下。
輸出數據如下。-
1.檢定統計數
2.p值
3.檢定統計數的拒絕極限(1%、5%、10%)
透過共整合進行配對交易
實際上,只用一種品種的話很難查到均值回歸性質。需要用2種品種之間的差確認是否會出現均值回歸性質。
如果在具有相關性的2種品種之間的點差出現均值回歸的話,可以利用多空組合來獲利。
共整合ADF檢定就是可以尋找提供此類交易機會的貨幣對的統計方法。
共整合ADF檢定就是對2種時間序列數據進行線形回歸,檢定殘差序列的靜止性。
當2個時間序列數據的線形組合是一個靜止過程時,線形回歸的殘差序列也是靜止的。
下面介紹一個使用Python的statsmodels庫進行共整合ADF檢定的示例。
```
import yfinance as yf
import pandas as pd
import statsmodels.tsa.stattools as ts
# 獲取每個貨幣對的數據
pairs = ['AUDJPY=X', 'CADJPY=X']
fx_data = {}
for pair in pairs:
data = yf.download(pair, start='2022-01-01', end='2023-01-01')
fx_data[pair] = data['Close']
merged_data = pd.DataFrame(fx_data)
# 刪除缺失值
merged_data.dropna(inplace=True)
# 共整合ADF検定
eg_test_result = ts.coint(merged_data['AUDJPY=X'], merged_data['CADJPY=X'])
# 顯示結果
print('T-statistic:', eg_test_result[0])
print('p-value:', eg_test_result[1])
print('Critical Values:')
critical_value_labels = ['1%', '5%', '10%']
for i, value in enumerate(eg_test_result[2]):
print('\t%s: %.3f' % (critical_value_labels[i], value))
```
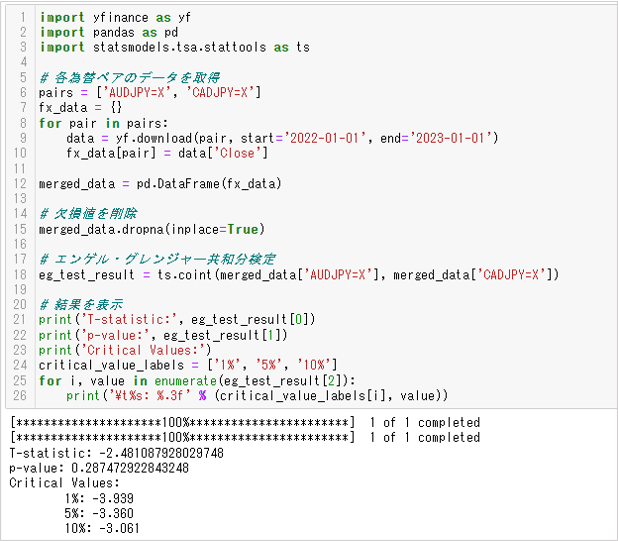
輸出數據如下。
-
1.檢定統計數
2.p值
3.極限值
利用以上步驟來需要擁有與共整合相關的貨幣對,當找到的貨幣對的點差暫時擴大做多或做空,等待均值回歸,這樣就可以進行超出預期值的交易(配對交易)。
做多或做空的時機
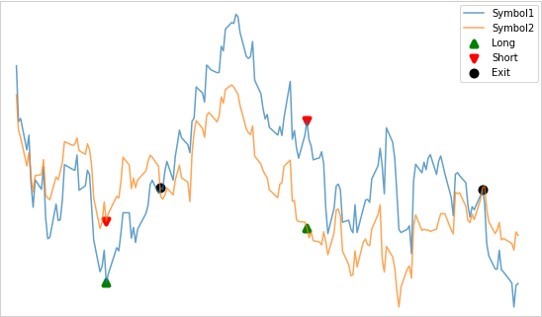
對於根據共整合ADF檢定找出與共整合相關的貨幣對後,就可以使用均值回歸策略。只需要在「殘差時間序列圖」上畫一條顯示平均值和標準偏差的水平線,就可以利用它來確定下單的時機。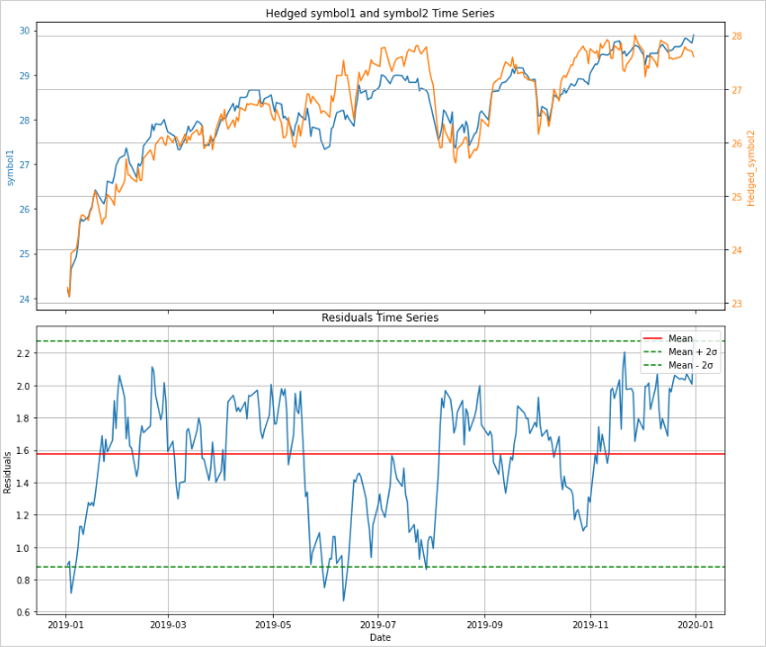
上方的曲線圖是重疊顯示了用共整合ADF檢定找出的貨幣對(symbol1和symbol2)的價格變動。下方的曲線圖是當貨幣對回歸時的殘差時間序列圖。
在平均值與平均值之間畫一條±2σ的水平線。
在+2σ線的上方時賣出symbol1、同時買入symbol2,然後等待均值回歸時的價格變動。
下面介紹如何利用布林通道來確認交易時機。
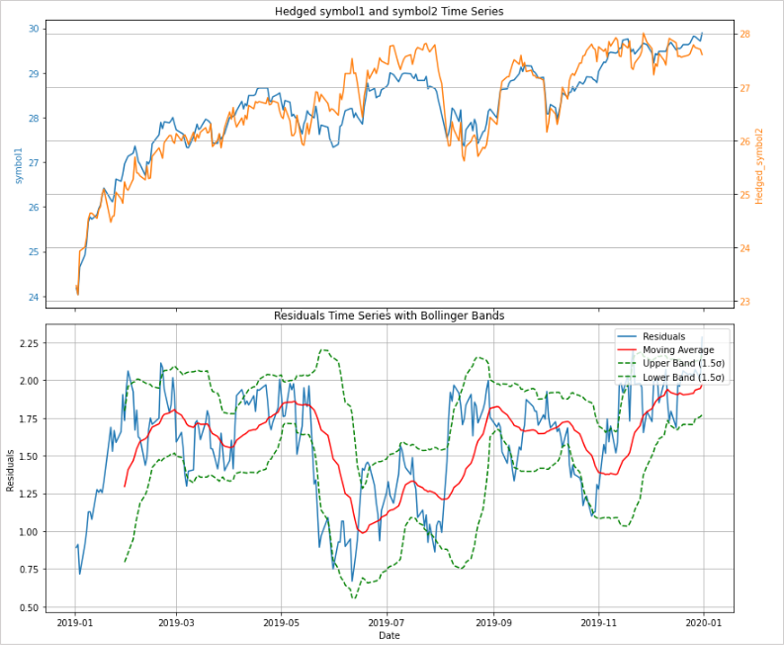
如果按照一般的方法,當觸及布林通道的上軌或下軌時反向交易的話,在有趨勢的行情中會出現巨大虧損,而且在隨機走勢中也沒有任何優勢。
處於共整合關係中的貨幣對會有靜態殘差序列,就像是在震盪行情中使用布林通道做反向交易一樣。
如何尋找統計套利交易的機會
資源國際貨幣與一部分的大宗商品配對時,有可能會出現相關性。下圖是根據共整合檢定的p值所計算出的多個資源國際貨幣與大宗商品配對時的相關性。
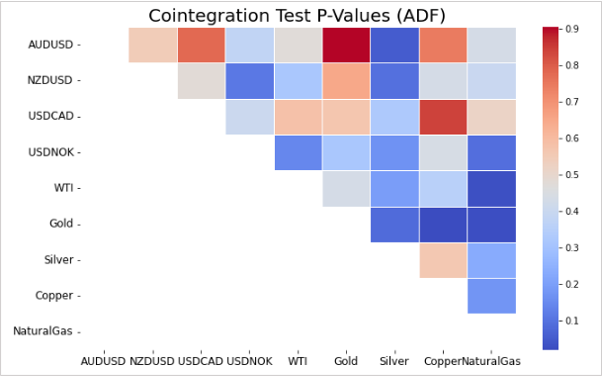
因為p值越低共整合相關性的可能性越高,所以上圖中的深藍色配對組合屬於這種情況。
這樣用相關性圖顯示出來的話,就可以更加有效的找到配對組合。
下圖是顯示共整合檢定的p值時間變化。
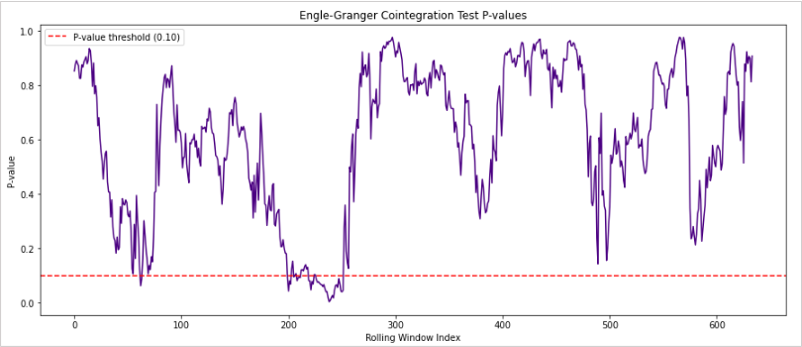
雖然上圖數據的配對組合並不是整體上都有共整合關係,但是,可以看出p值下降的時機存在週期性。
即使只是暫時會出現統計套利交易的機會,如果這個時機可以預測的話就有交易的可能性。
評價性能時的注意點
並不只限於統計套利交易,在其他交易中也是,如果想要用過去的歷史數據來評價策略的表現的話,需要複製現實情況進行測試才可以。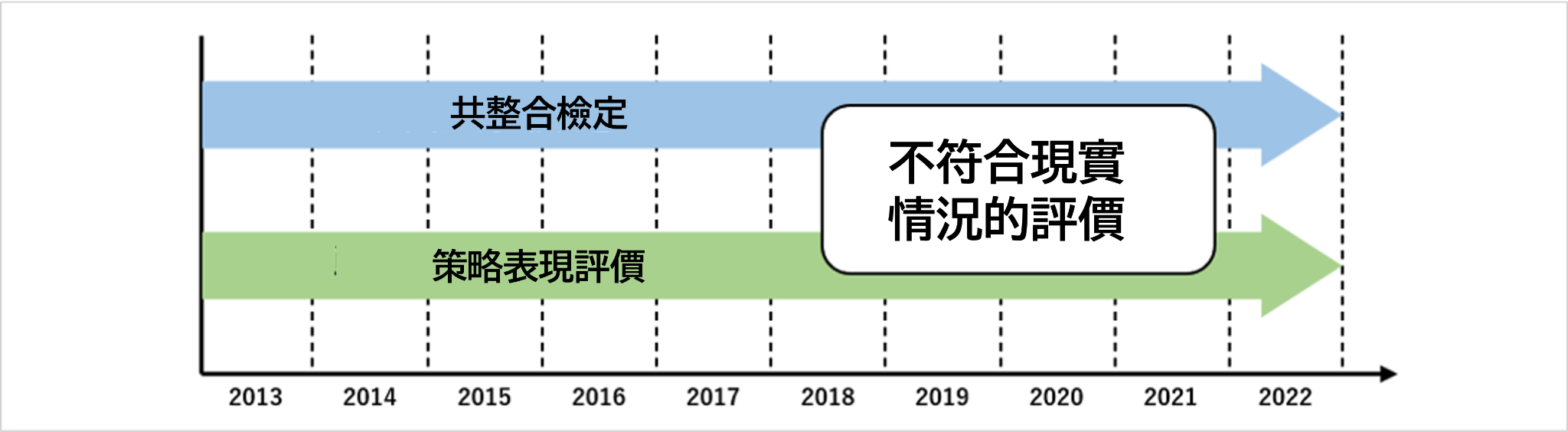
如上圖所顯示的策略表現,如果在共整合檢定時,事前已經知道「在這一期間會出現均值回歸」,然後用相關策略進行測試的話,就會成為失敗的檢定。
在現實情況中,在開始交易之前還不知道什麼時候會出現均值回歸,需要預測「會出現均值回歸」,然後用相關策略進行交易。
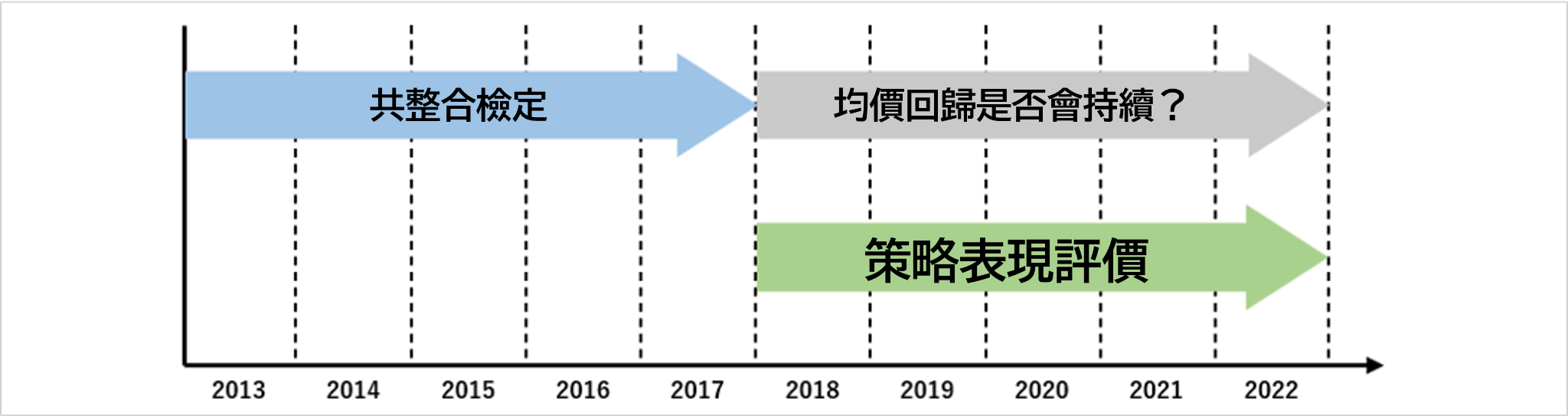
上圖顯示,透過共整合檢定發現均值回歸的配對組合後,預測「隨後的期間也會持續均值回歸」,然後用相關策略進行交易,這樣的測試就再現了現實情況。
關於統計套利交易的研究
配對交易或統計套利交易自20世紀80年代以來一直被用於交易中,許多量化交易者和研究人員也從那時起對其進行了開發。現在,其中很多都融入了機器學習技術。
在此介紹部分文獻。
Kitapbayev Y. and Leung T. (2017).「Optimal mean-reverting spread trading: nonlinear integral equation approach.」
關於下單和平倉的時間會有多種方法。
以上文獻中介紹,在OU過程(Ornstein-Uhlenbeck process 均值回歸的隨機過程 )中應用最佳停止問題,透過衡量下單和平倉的時間來實現高收益。
Beckmann J, Czudaj R, Arora V (2017) 「The Relationship Between Oil Prices And Exchange Rates: Theory And Evidence」
出現共整合關係的背景是對於相關品種的當前價格,可以用另一個配對品種來評價是否被高估或低估。
以上文獻研究了原油價格和外匯匯率之間的相互影響關係。
為原油價格和外匯匯率之間是否存在以上的高估或低估關係提供了線索。
Figueira M, and Horta N (2022)「Machine Learning-Based Pairs Trading Strategy with Multivariate」
以上文獻提供了可以利用機器學習(ARIMAとXGBoost)从2種以上的品種的多變量配對組合的點差中發現交易機會的方法。
統計套利交易雖然是從相對價格評價中發現也預測的機會,但並不一定是2種品種。
如果點差存在可預測的週期或模式的的話,也不一定需要均值回歸策略。
關於多變量配對組合(Johansen檢定)
本篇文章雖然介紹了共整合ADF檢定(Engle-Granger檢定),其實還有另外一種方法就是Johansen檢定(Johansen test)。Engle-Granger的方法是分析2個變量的共整合,而Johansen的方法是同時推測和分析3個變量以上的共整合。
以下Python源碼是Johansen檢定的示例。
```
import yfinance as yf
import pandas as pd
from statsmodels.tsa.vector_ar.vecm import coint_johansen
# 獲取每個貨幣對的數據
pairs = ['AUDJPY=X', 'CADJPY=X', 'NZDJPY=X']
fx_data = {}
for pair in pairs:
data = yf.download(pair, start='2022-01-01', end='2023-01-01')
fx_data[pair] = data['Close']
merged_data = pd.DataFrame(fx_data)
# 刪除缺失值
merged_data.dropna(inplace=True)
# Johansen共整合檢定
result = coint_johansen(merged_data, det_order=0, k_ar_diff=1)
# 顯示結果
print("\n\n追蹤檢定統計量:")
for i, trace_stat in enumerate(result.lr1):
print(f"r = {i}: {trace_stat}")
print("\n追蹤檢定的極限:")
for i, trace_crit in enumerate(result.cvt):
print(f"r = {i}: 1% = {trace_crit[0]}, 5% = {trace_crit[1]}, 10% = {trace_crit[2]}")
print("\n最大特徵值檢定統計量:")
for i, max_eig_stat in enumerate(result.lr2):
print(f"r = {i}: {max_eig_stat}")
print("\n最大特徵值檢定的極限:")
for i, max_eig_crit in enumerate(result.cvm):
print(f"r = {i}: 1% = {max_eig_crit[0]}, 5% = {max_eig_crit[1]}, 10% = {max_eig_crit[2]}")
```
共整合ADF檢定會進行2個變量回歸。
也就是,一個是因變量,另一個是解釋變量,但當樣本量較小時,因變量和解釋變量調換,結果就會發生變化。
另外, 還沒有建立系統的程序來推測3個變量以上的共整合。
Johansen檢定因為不需要共整合AD檢定的兩階段程序,所以不會出現這些問題,可以檢定多變量配對組合。
3種以上品種的多變量配對組合之間確實存在相關性,其點差中可能會出現可預測的週期或模式,例如,有可能會出現領先或落後等關係。
將EA自動程式交易應用於外匯與差價合約交易中

我們以圖文形式詳細介紹有關EA自動程式交易的基本知識,以及在MT4/MT5平台上的安裝、參數設定方法、編碼等等內容。另外,對持有OANDA帳戶的客戶,還可以免費使用我們的獨有EA與指標工具。




